
Performance comparison of SOTA MLLMs on MMR-Life.
 MMR-Life
MMR-Life
Piecing Together Real-life Scenes for Multimodal Multi-image Reasoning
2,646 Questions
Multi-image reasoning tasks from daily scenes.
19,108 Images
Household, dining, sports, and real-life contexts.
7 Reasoning Types
Abductive / Analogical / Causal / Deductive / Inductive / Spatial / Temporal.
37 Models Evaluated
Open-source & proprietary MLLMs under unified protocols.
🔔News
📢[2026-02-27] Officially open-sourced the paper, dataset, and code.
🎉[2026-01-26] Our paper was accepted to ICLR 2026.
Introduction
Recent progress in the reasoning capabilities of multimodal large language models (MLLMs) has empowered them to address more complex tasks such as scientific analysis and mathematical reasoning. Despite their promise, MLLMs’ reasoning abilities across different scenarios in real life remain largely unexplored and lack standardized benchmarks for evaluation. To address this gap, we introduce MMR-Life, a comprehensive benchmark designed to evaluate the diverse multimodal multi-image reasoning capabilities of MLLMs across real-life scenarios. MMR-Life consists of 2,646 multiple-choice questions based on 19,108 images primarily sourced from real-world contexts, comprehensively covering seven reasoning types: abductive, analogical, causal, deductive, inductive, spatial, and temporal. Unlike existing reasoning benchmarks, MMR-Life does not rely on domain-specific expertise but instead requires models to integrate information across multiple images and apply diverse reasoning abilities. The evaluation of 37 advanced models highlights the substantial challenge posed by MMR-Life. Even top models like GPT-5 achieve only 58% accuracy and display considerable variance in performance across reasoning types. Moreover, we analyze the reasoning paradigms of existing MLLMs, exploring how factors such as thinking length, reasoning method, and reasoning type affect their performance. In summary, MMR-Life establishes a comprehensive foundation for evaluating, analyzing, and improving the next generation of multimodal reasoning systems.
MMR-Life Benchmark
Dataset Overview
MMR-Life consists of 2,646 multiple-choice questions based on 19,108 images, comprehensively covering 7 reasoning types (i.e., abductive, analogical, causal, deductive, inductive, spatial, and temporal) and 21 tasks. Each task is based on a set of multi-images, predominantly sourced from real-life contexts, such as domestic life, daily dining, and sports activities. The questions in our benchmark do not require domain-specific expertise but instead ask models to extract key information from multiple real-life images and derive new conclusions. This design aligns MMR-Life more closely with the reasoning types found in everyday life.
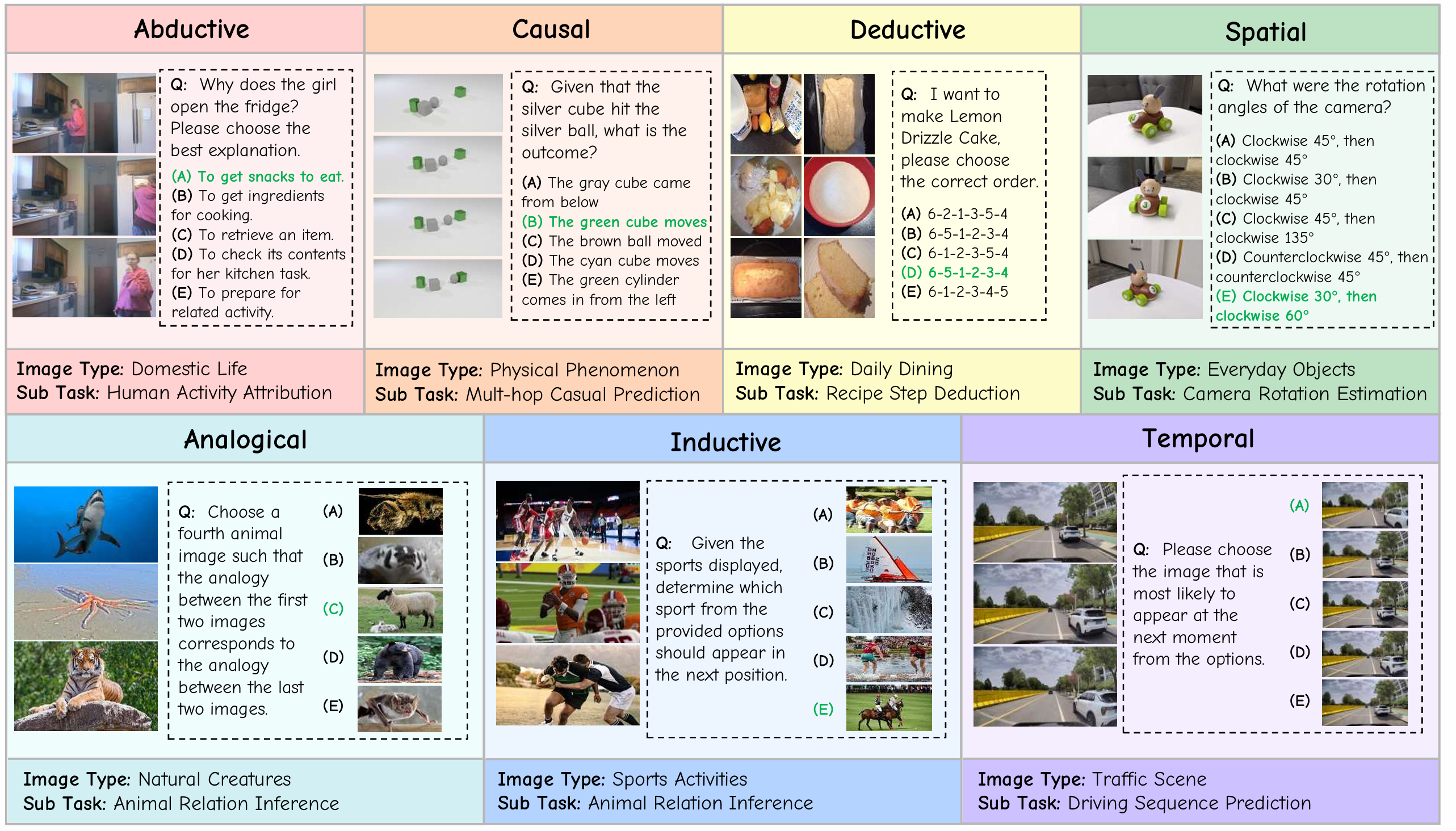
Real-world scenes
Multi-image inputs
Diverse Reasoning Types
General-Knowledge Reasoning
Experiment Results
Leaderboard
Error Analysis
We analyze failures of GPT-5 and Gemini-2.5-Pro across reasoning types. Reasoning errors dominate (32%), including causal inversion (24%), temporal confusion (42%), and missing steps (24%). Abstraction issues (17%) and knowledge gaps (17%) highlight the need for stronger long-horizon reasoning and recall; perception errors (12%) show difficulty in fine-grained visual cues.
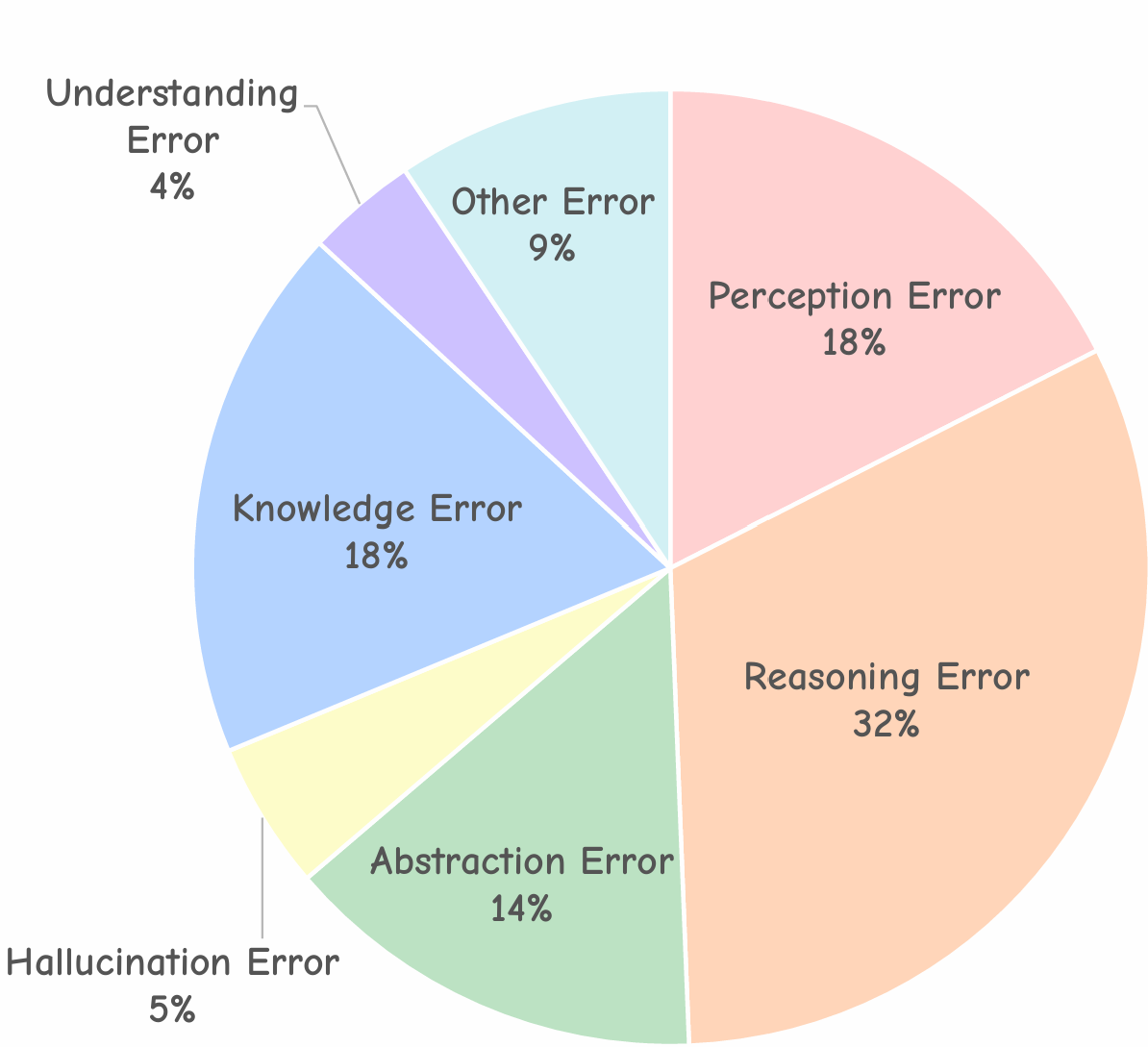
Error distribution over 140 annotated GPT-5 errors.

Error distribution over 140 annotated Gemini-2.5-Pro errors.
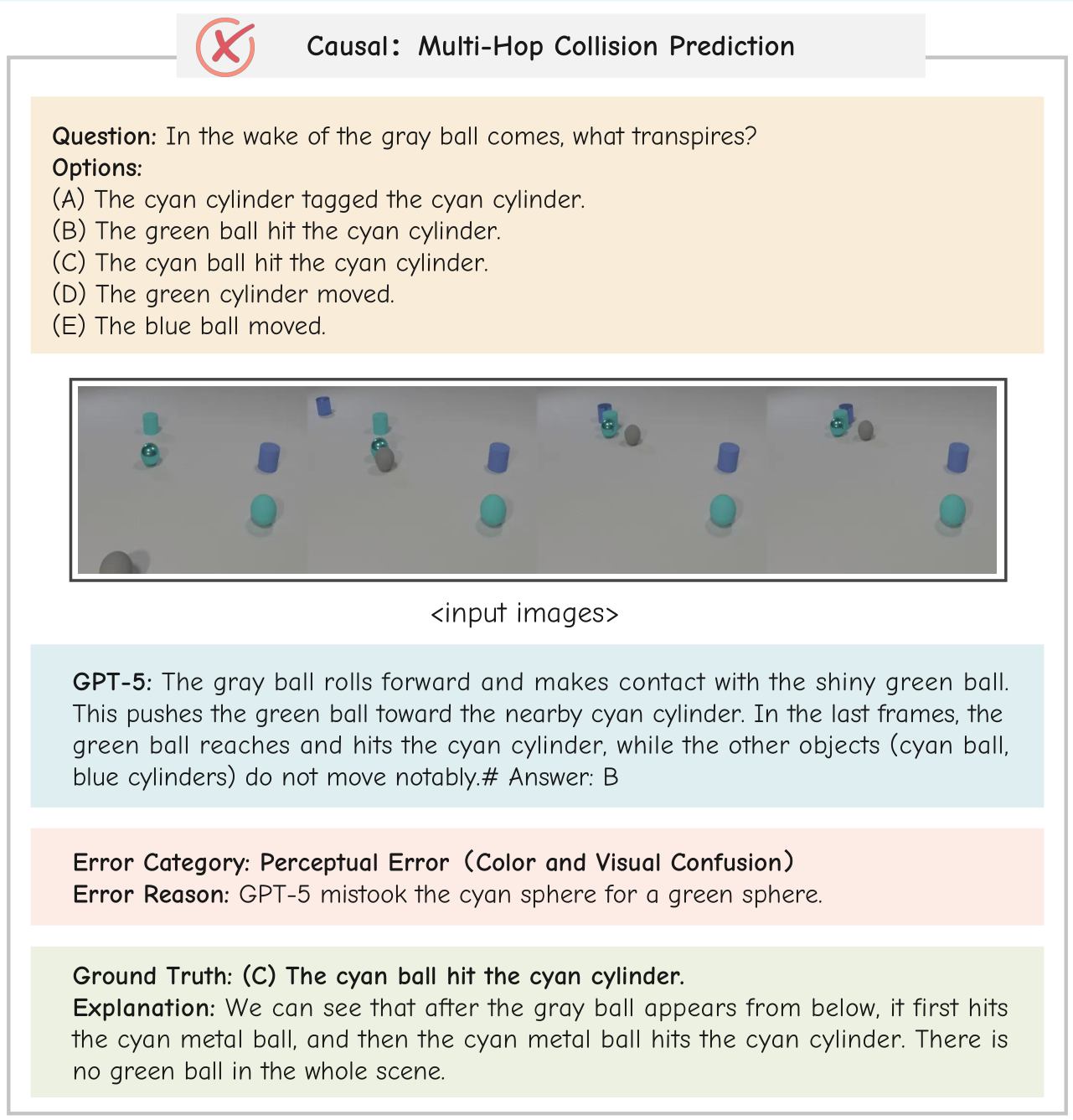
Error Examples




















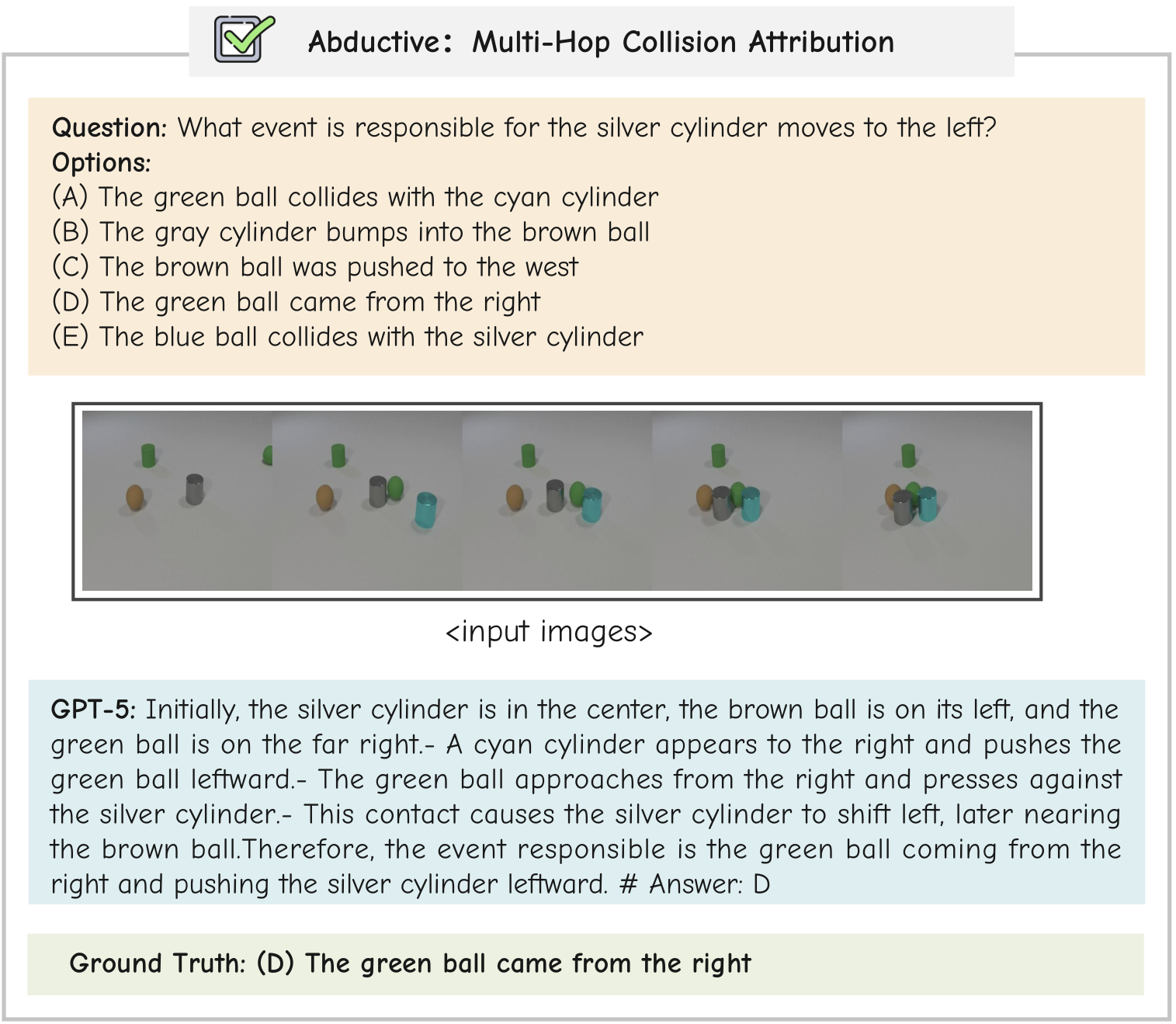
Correct Examples




















BibTeX
@misc{li2026mmrlifepiecingreallifescenes,
title={MMR-Life: Piecing Together Real-life Scenes for Multimodal Multi-image Reasoning},
author={Jiachun Li and Shaoping Huang and Zhuoran Jin and Chenlong Zhang and Pengfei Cao and Yubo Chen and Kang Liu and Jun Zhao},
year={2026},
eprint={2603.02024},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2603.02024},
}